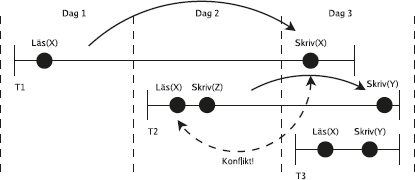
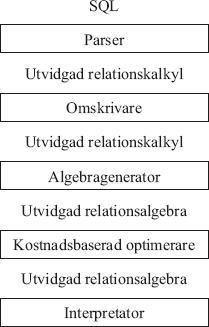
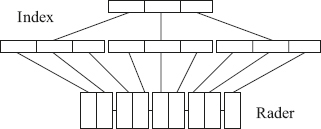
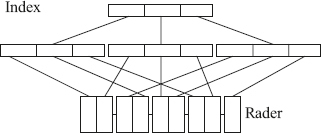
113
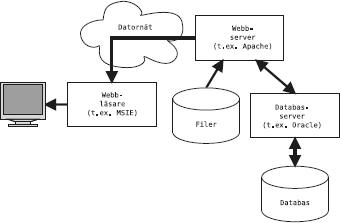
Det här kapitlet är en handledning till grunderna om hur man använder frågespråket SQL.
Ett frågespråk är ett språk som man använder för att ställa frågor till en databashanterare, dvs göra sökningar i en databas.
Mer avancerad användning av SQL, till exempel operationen yttre join, mer komplicerat arbete med aggregatfunktioner och rekursiva frågor, tas upp i nästa kapitel.
Det kan vara bra att läsa avsnittet om relationsmodellen innan man läser det här kapitlet.
114
Med början 1986 har man arbetat på att standardisera SQL.
Den första standarden som blev mer allmänt accepterad antogs 1992, och kallades SQL-92 eller SQL2.
En kraftigt utökad standard antogs 1999, och kallades SQL:1999 eller SQL3.
Även om det kommit flera senare standarder, är både SQL-92 och SQL:1999 fortfarande en sorts riktmärken, och man talar ibland fortfarande om hur väl olika databashanterare uppfyller SQL-92.
Inte minst beror det på att det finns en officiell valideringstest för att uppfylla SQL-92-standarden
1
men inte för senare SQL-versioner.
Mimer tillhandahåller dock en allmänt accepterad validerare även för SQL:1999.
2
Den SQL-standard som gäller när detta skrivs fastställdes 2016 och kallas ISO/IEC 9075:2016, eller SQL:2016.
Den är uppdelad i nio olika delar, och som exempel är det fullständiga namnet på den första delen ISO/IEC 9075-1:2016 Information technology – Database languages – SQL – Part 1: Framework (SQL/Framework).
Bara denna inledande del, på 78 sidor, kostar över 1 500 kronor att köpa.
(Standardiseringsarbetet finansieras delvis genom försäljning av standarddokumenten.)
Sammanlagt består SQL:2016 av flera tusen sidor.
Dessutom finns standarden ISO/IEC 13249, "SQL Multimedia and Application Packages", som beskriver datatyper för användningsområden som multimedia och data mining, och ISO/IEC TR 19075, som är en serie tekniska rapporter som beskriver SQL-stöd för en del specialiserade tekniker, till exempel reguljära uttryck.
Tyvärr följer de flesta av de existerande databashanterarna inte SQL-standarden särskilt exakt, utan de har sina egna dialekter.
Grunderna, till exempel de jämförelsevis enkla sökningar som tas upp i det här kapitlet, är för det mesta lika och i överensstämmelse med vad standarden säger, men en så enkel sak som att ange hur många rader från svaret som ska tas med görs fortfarande på helt olika sätt i olika databashanterare.
När det gäller mer avancerade saker, som triggers och lagrade procedurer, kan skillnaderna mellan olika SQL-dialekter vara stora.
Det är nämligen inte så att man har hittat på en standard, och sen har ett antal tillverkare byggt databashanterare som följer den standarden.
I stället har de stora databashanterarna,
115
till exempel Oracle och Db2, funnits mycket längre än standarden, och SQL-standarden får nog närmast ses som en kompromiss mellan de olika stora tillverkarna av databashanterare, där var och en helst ville få just sin dialekt och just sina finesser upphöjda till standard.
Det gör att det kan vara mycket arbete att byta från en databashanterare till en annan.
Ge följande kommando till databashanteraren:
select * from Medlemmar;
Det här kommandot, även kallat en SQL-fråga eller select-fråga, betyder ungefär "välj ut alla kolumnerna ur tabellen Medlemmar". Semikolonet på slutet ingår egentligen inte i kommandot, men behövs ibland för att markera slutet på frågan eller för att skilja olika SQL-kommandon åt.
Det har blivit en konvention i många sammanhang att skriva nyckelorden i SQL med stora bokstäver (versaler), som i SELECT och FROM, men av läsbarhetsskäl har vi valt att använda små bokstäver (gemener).
116
När du kör frågan kommer du som svar att få en tabell som liknar den här:
Alla select-frågor ger en tabell som svar. Även om svaret (som vi kommer att se exempel på senare) bara består av ett enda värde, får man det i form av en tabell. Frågorna utgår från en eller flera tabeller (i det här fallet tabellen Medlemmar), och sammanställer eller väljer ut information som alltså resulterar i en ny tabell.
Exakt hur man gör för att "köra frågan" beror på vilken databashanterare man använder.
På vissa system finns kanske ett särskilt fönster där man kan skriva in och redigera frågan, varefter man kör den genom att klicka med musen på en knapp som det står Kör på.
I andra system skriver man in frågan, avslutar den med ett semikolon (;), och sen körs frågan när man trycker på returtangenten.
Det är också vanligt med SQL-frågor inbakade i ett program som skrivits i ett vanligt programmeringsspråk som C eller Java, men det tar vi upp i ett senare kapitel.
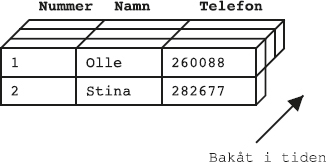
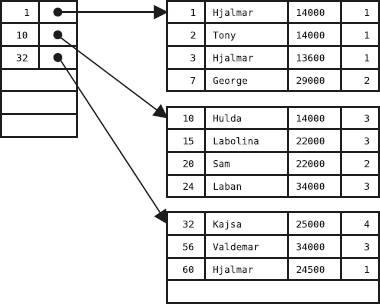
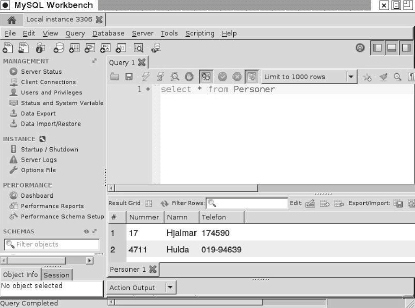
Det här är alltså innehållet i tabellen Medlemmar i databasen.
Den tabellen innehåller data om klubbens medlemmar.
Varje rad beskriver en medlem.
Som vi ser har tabellen tre kolumner, nämligen Mnr (medlemsnummer), Namn (medlemmens namn) och Telefon (medlemmens telefonnummer).
Notera att raderna i svaret inte kommer i någon särskild ordning.
Varje rad (eller tupel) beskriver en sak av något slag, i det här fallet en medlem i idrottsklubben, och varje kolumn (eller attribut) beskriver en egenskap hos en sådan sak, exempelvis dess nummer eller namn.
117
Alla värden i samma kolumn har samma typ, till exempel heltal eller textsträng med en viss längd, och mängden av alla värden som kan finnas i kolumnen brukar vi kalla domän.
Det motsvarar ungefär begreppet datatyp i programmeringsspråk.
Med hjälp av SELECT kan vi mer detaljerat beskriva vad vi vill ha för svar.
Om vi till exempel bara vill ha reda på namnen på klubbens medlemmar, alltså kolumnen Namn i tabellen Medlemmar, skriver vi:
select Namn from Medlemmar;
Med kommandot "select Namn from Medlemmar" menar vi helt enkelt "välj ut kolumnen Namn ur raderna i tabellen Medlemmar".
Vi kan välja ut mer än en kolumn om vi vill, till exempel namnet och telefonnumret (kolumnerna Namn och Telefon):
select Namn, Telefon from Medlemmar;
Den första frågan vi ställde, "select * from Medlemmar", skulle också kunna uttryckas så här:
118
select Mnr, Namn, Telefon
from Medlemmar;
Vi har nu sett hur man kan använda select för att välja ut dem av tabellens kolumner som man är intresserad av.
Men vi kan också tala om vilka rader vi vill ha med i svaret.
Om vi vill ha information bara för den medlem som heter Lotta, skriver vi:
select * from Medlemmar
where Namn = 'Lotta';
Med ordet where kan vi alltså ange ett sökvillkor som talar om vilka rader vi är intresserade av.
Vi skulle kunna omformulera frågan så här:
select * from Medlemmar
where Medlemmar.Namn = 'Lotta';
Medlemmar.Namn betyder här "kolumnen Namn i tabellen Medlemmar", men eftersom det än så länge inte kan uppstå några missförstånd räcker det med att skriva Namn, utan någon tabellangivelse.
Vi kan också göra strängmatchning med jokertecken (eller wildcards som det heter på engelska):
select Namn, Telefon from Medlemmar
where Namn like 'S%';
119
Om man använder ordet like i jämförelsen, innebär det strängmatchning med jokertecken.
Understreck ("_") betyder ett tecken, vilket som helst, medan procenttecken ("%") betyder en följd av noll, ett eller flera av vilka tecken som helst.
5
Om man i stället använder likhetstecken ("=") som vanligt, får man en vanlig, exakt jämförelse i stället för mönstermatchning.
Följande fråga söker efter medlemmar med det säkert ovanliga namnet S%:
select Namn, Telefon from Medlemmar
where Namn = 'S%';
Man kan bygga upp mer komplicerade where-villkor med hjälp av and och or, på samma sätt som man brukar kunna göra i andra programmeringsspråk:
select * from Medlemmar
where Namn like 'S%' and Mnr <= 2
or Telefon = '174590';
Således har and högre prioritet (är klibbigare) än or.
Uttrycken kan grupperas med parenteser:
select * from Medlemmar
where Namn like 'S%' and (Mnr <= 2
or Telefon = '174590');
120
SQL använder enkla citationstecken, som i 'Lotta', för att avgränsa strängar, inte dubbla som i "Lotta".
I en del databashanterare fungerar det med dubbla citationstecken också, men dubbla citationstecken ska egentligen användas för kolumn- och tabellnamn, om de namnen är reserverade ord eller innehåller otillåtna tecken:
select "select", "Glö glö glö"
from "Åiåaäeö";
Normalt skiljer SQL inte på stora och små bokstäver i tabell- och kolumnnamn, men när man sätter dem inom citationstecken är stora och små bokstäver olika.
Många databashanterare översätter internt alla namn till stora bokstäver, och då måste man skriva med stora bokstäver innanför citationstecknen.
En del SQL-dialekter skiljer sig från standarden. Exempelvis använder MySQL bakåtvända enkla citationstecken, som i 'Åiåaäeö', och Microsoft SQL Server använder hakklamrar, som i [Åiåaäeö].
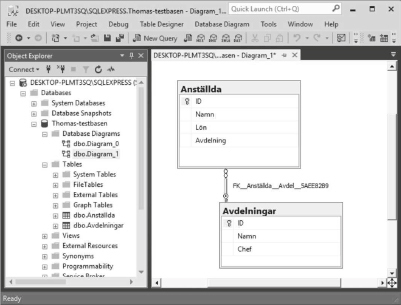
Vi har en tabell till i databasen, nämligen tabellen Sektioner som beskriver idrottsklubbens olika sektioner:
select * from Sektioner;
Varje rad i tabellen Sektioner innehåller data om en av klubbens sektioner.
Tabellen har tre kolumner, nämligen Skod (sektionskod), Namn (sektionens namn) och Ledare (vem som är ledare för sektionen).
Kolumnen Ledare anger medlemsnumret på den medlem som är ledare för sektionen.
Vi ser till exempel att medlem nummer 4 leder bowlingsektionen, och vi kan sen gå till medlemstabellen för att ta reda på vem medlem nummer 4 är.
Som vi kanske kommer ihåg såg medlemstabellen ut så här:
Vi ser alltså att det är Lotta som leder bowlingsektionen.
122
Tabellerna i exemplet är så små att vi direkt ser att ledaren för bowlingsektionen är Lotta.
Men om det är stora tabeller vill man förstås använda SQL-frågor för att få fram den informationen.
Vi ska nu försöka oss på att göra detta.
Vi börjar med det mest uppenbara (men inte särskilt bra) sättet.
Först tar vi fram numret på bowlingsektionens ledare:
select Ledare from Sektioner
where Namn = 'Bowling';
Och sen söker vi helt enkelt i medlemstabellen efter vem nummer4 är:
select Namn from Medlemmar
where Mnr = 4;
Det är dock onödigt att ställa två separata frågor.
I andra fall kan det dessutom bli väldigt arbetsamt, till exempel om man har stora mellanresultat som måste kopieras till nästa fråga.
I den andra frågan, "select Namn from Medlemmar where Mnr = 4", var ju 4:an resultatet av den första frågan, "select Ledare from Sektioner where Namn = 'Bowling'". Därför stoppar vi in denna första fråga i den andra frågan, i stället för 4:an!
select Namn from Medlemmar
where Mnr = (select Ledare from Sektioner where Namn = 'Bowling');
123
Notera att vi behövde skriva parenteser runt den andra, inre frågan.
Den kallas underfråga, inre fråga, sub-fråga eller sub-select.
Egentligen borde vi inte använda likhetstecken ("=") vid jämförelsen mellan Mnr och resultatet av den inre frågan, utan nyckelordet in.
Det skulle kunna finnas flera sektioner som heter "Bowling", och därigenom flera ledare, och om den inre frågan ger flera rader som svar fungerar inte jämförelse med likhetstecken.
Men mer om detta senare.
Nu ska vi göra samma sak utan någon inre fråga i where-villkoret.
Prova först att skriva båda tabellerna Sektioner och Medlemmar efter from i select-frågan:
select * from Sektioner, Medlemmar;
Resultatet blir den så kallade kartesiska produkten av de två tabellerna, dvs alla kombinationer av rader.
Det var ju inte det vi ville ha, så vi ändrar frågan så att den i stället väljer ut bara de rader där ledarnumret Ledare är samma som medlemsnumret Mnr:
select * from Sektioner, Medlemmar
where Ledare = Mnr;
124
Vi har plötsligt fått en fin liten tabell där varje rad innehåller information om en sektion och dess ledare.
Om vi vill, kan vi se det som att vi slagit ihop varje rad i tabellen Sektioner med den rad som den hör ihop med i tabellen Medlemmar.
Lottas rad kom med två gånger, men det är inget konstigt med det, för hon är ledare för två sektioner.
Vi var ju egentligen bara intresserade av bowlingsektionens ledare, så vi lägger in det också i where-villkoret:
select * from Sektioner, Medlemmar
where Ledare = Mnr
and Sektioner.Namn = 'Bowling';
Och så gör vi en sista ändring, för att bara få med namnet på ledaren:
select Medlemmar.Namn from Sektioner, Medlemmar
where Ledare = Mnr
and Sektioner.Namn = 'Bowling';
En fråga där man kombinerar (joinar) två tabeller går alltså att skriva på minst två olika sätt: antingen med bägge tabellerna på fromraden
8
och hopkopplade i where-villkoret, eller med en inre fråga
125
som vi såg i förra avsnittet. Man talar om flata respektive nästlade frågor.
Internt i databashanteraren kommer båda frågorna att hanteras på samma sätt, så det finns inga prestandaskäl till att välja det ena eller andra sättet.
9
En komplicerad sökning med många inre frågor kan bli svårhanterlig.
Välj det som är lättast att formulera och lättast att förstå, vilket oftast är flata frågor.
Det här är grunden för hur man skriver enkla SQL-frågor:
Så här:
select A, B, C
from T1, T2, T3
where VILLKOR
En SQL-fråga kan inte köras steg för steg som ett C- eller Javaprogram, utan den måste först översättas av databashanteraren till en så kallad exekveringsplan.
Men om man känner sig mer hemma med steg-för-steg-språk, skulle man kunna skriva om SQL-frågan ovan som ett litet program med nästlade loopar, dvs loopar inuti varandra:
for each t1 in T1 do:
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfor each t2 in T2 do:
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfor each t3 in T3 do:
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xif VILLKOR then:
print A, B, C
126
I ovanstående pseudokod
10
betyder for each t1 in T1 do att vi loopar igenom alla raderna i tabellen T1, och använder t1 som loopvariabel. if-satsen längst in kommer alltså att köras en gång för varje tänkbar kombination av raderna i de tre tabellerna.
Om tabellerna innehåller tusen rader var, kommer if-satsen alltså att köras en miljard gånger.
(Databashanteraren kommer dock för det mesta att verkligen köra frågan på ett helt annat och snabbare sätt, men svaret blir detsamma.
Ordningen på raderna i resultatet kan visserligen bli en annan, men det gör inget, för ordningen spelar ju ingen roll: resultatet av en fråga anses vara detsamma oberoende av radernas ordning.)
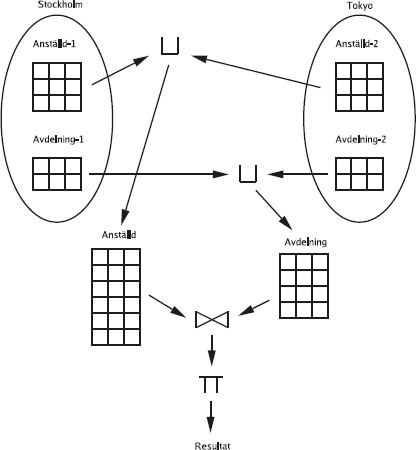
Nu ska vi prova på ännu en fråga som kräver att man kombinerar flera tabeller.
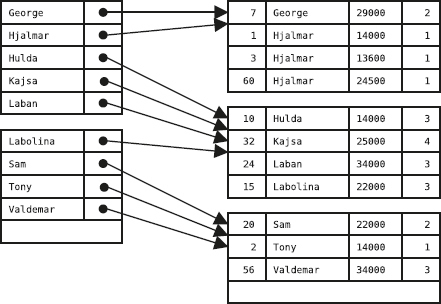
Först tittar vi på den nya tabellen Deltar, som innehåller data om vilka medlemmar som deltar i de olika sektionernas verksamhet:
select * from Deltar;
Av den första raden i tabellen ser vi att medlem nummer 1 deltar i sektionen med sektionskoden A. På nästa rad står det att (samma) medlem nummer 1 även deltar i sektionen med sektionskoden B. Och så vidare.
Den som kommer ihåg datamodellering med ER-modellen känner igen detta som ett många-till-många-samband mellan medlemmar och sektioner: en medlem kan delta i flera sektioner, och en sektion kan ha flera deltagande medlemmar.
Nu vill vi använda alla tre tabellerna i databasen (Medlemmar, Sektioner och Deltar) för att svara på frågan Vilka sporter ägnar sig Olle åt?
127
Först gör vi på det dumma sättet, och börjar med att ta reda på Olles medlemsnummer:
select Mnr
from Medlemmar
where Namn = 'Olle';
Sen tittar vi i tabellen Deltar för att få reda på vilka av sektionerna som Olle deltar i.
select Sektion from Deltar
where Medlem = 1;
Ok, så vad är 'A', 'B' och 'C' för nåt?
select Namn from Sektioner
where Skod = 'A'
or Skod = 'B'
or Skod = 'C';
Vi kan skriva samma fråga lite enklare med hjälp av nyckelordet in:
select Namn from Sektioner
where Skod in ('A', 'B', 'C');
Det var alltså det dumma sättet. Nu ska vi i stället skriva ihop de tre frågorna till en enda fråga. Först stoppar vi in en inre fråga för att slippa det hårdkodade "('A', 'B', 'C')":
128
select Namn from Sektioner
where Skod = (select Sektion
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Deltar
where Medlem = 1);
Vi får ett felmeddelande.
Så här ser det ut i databashanteraren Mimer:
Mimer SQL error -10107 in function DYNAMIC FETCH
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xThe result of a subquery or select into is more
than one row
Vi måste använda "in" i stället för "=". Den vanliga lika-med-jämförelsen med "=" kan nämligen bara jämföra med ett värde, och här är det ju tre (eftersom Olle deltar i tre sektioner). Använd alltid "in" i stället för "=" för att jämföra med resultatet från en inre fråga!
select Namn from Sektioner
where Skod in (select Sektion
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Deltar
where Medlem = 1);
Och så stoppar vi in den första frågan, "select Mnr from Medlemmar where Namn = 'Olle'", i stället för 1:an:
select Namn from Sektioner
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xwhere Skod in (select Sektion
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Deltar
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xwhere Medlem in (select Mnr
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Medlemmar
where Namn = 'Olle'));
Därmed är frågan färdig, och eftersom det är en enda fråga kan den behandlas snabbt och effektivt av databashanteraren.
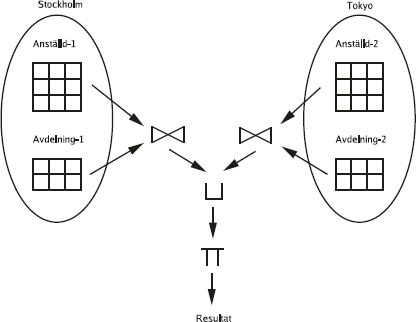
Vi kan också skriva samma sak som en flat fråga, dvs utan någon inre fråga.
Ett första försök:
129
select Namn from Sektioner, Deltar, Medlemmar
where Skod = Sektion
and Medlem = Mnr
and Namn = 'Olle';
Vi får ett felmeddelande
11
som kan se ut så här:
1: select Namn from Sektioner, Deltar, Medlemmar
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#x^
Mimer SQL error -12204 in function PREPARE
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xColumn reference Namn ambiguous
4: and Namn = 'Olle'
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#x^
Mimer SQL error -12204 in function PREPARE
Column reference Namn ambiguous
"Ambiguous" betyder "tvetydig".
Och mycket riktigt finns det två olika kolumner som heter Namn, en i tabellen Medlemmar och en i tabellen Sektioner.
Därför måste man ange vilken av de båda Namn-kolumnerna det är man menar.
Vi skriver om frågan så det blir rätt:
select Sektioner.Namn
from Sektioner, Deltar, Medlemmar
where Skod = Sektion
and Medlem = Mnr
and Medlemmar.Namn = 'Olle';
Notera att where-villkoret som vanligt dels kopplar ihop de olika tabellerna, dels gör ett urval av vilka rader i resultatet vi är intresserade av.
Det behövs två villkor för att koppla ihop tre tabeller, och ytterligare ett villkor för att bara behålla Olle-raderna i svaret.
130
Vilka deltar i någon (det vill säga minst en) sektion?
Jo, det är förstås de medlemmar vars medlemsnummer förekommer i Deltartabellens Medlem-kolumn:
select * from Medlemmar
where Mnr in (select Medlem from Deltar);
Frågan kan också, som vanligt, skrivas om utan någon select-sats i where-villkoret:
select distinct Medlemmar.Mnr, Medlemmar.Namn,
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xMedlemmar.Telefon
from Medlemmar, Deltar
where Medlemmar.Mnr = Deltar.Medlem;
Nyckelordet distinct tar bort dubbletter, och behövs eftersom medlemmar som deltar i flera sektioner annars kommer med flera gånger i svaret. I den ursprungliga teoretiska relationsmodellen byggde relationerna på mängder av tupler, och därför fick man aldrig dubbletter i svaret, men i modernare formuleringar av relationsmodellen, och i SQL, arbetar man inte med vanliga mängder utan med multimängder (även kallade påsar, efter engelskans "bag"), som kan innehålla dubbletter. Resultatet av en select-sats är således en mängd om man specificerar distinct och en påse om man inte gör det.
Om vi vill veta vilka som inte deltar i någon sektion, ändrar vi bara in till not in:
select * from Medlemmar
where Mnr not in (select Medlem from Deltar);
En fråga som innehåller "... in (select ..." kunde skrivas om med en vanlig likhet. Men "... not in (select ..." är svårare att skriva om. Frågan ovan kan inte skrivas om så här:
select distinct Medlemmar.Mnr, Medlemmar.Namn, Medlemmar.Telefon
131
from Medlemmar, Deltar
where Medlemmar.Mnr <> Deltar.Medlem;
Den frågan tar inte fram vilka som inte sportar, utan den tar fram alla medlemmar som inte är helt ensamma om att sporta!
(Tänk så här: Varje medlem som går att para ihop med en rad i Deltartabellen som inte handlar om henne själv.)
Förutom in finns det en hel rad med nyckelord som kan användas i samband med en underfråga i SQL: exists, any, some och all.
exists används för att avgöra om underfrågan ger några rader som svar. Till exempel kan man göra samma sak som i förra avsnittet, nämligen ta reda på vilka medlemmar som deltar i någon (det vill säga minst en) sektion. Det är ju samma sak som att fråga för vilka medlemmar det existerar rader i Deltar-tabellen:
select * from Medlemmar
where exists (select * from Deltar
where Deltar.Medlem = Medlemmar.Mnr);
Lägg märke till hur den yttre frågan kan "användas" i den inre frågan!
Om den inre frågan stod för sig själv,
select * from Deltar
where Deltar.Medlem = Medlemmar.Mnr;
skulle den ge ett felmeddelande. Tabellen Medlemmar nämns inte i from-listan, och kan därför inte användas i frågan. I stället kan man se det som att den yttre frågan körs, och sen körs den inre frågan en gång för varje rad i den yttre frågan.
12
Då har man också tillgång till kolumnen Medlemmar.Mnr, från den yttre frågan, och kan använda den i where-villkoret i den inre frågan.
132
En underfråga som är sammankopplad med en yttre fråga på det här sättet, och alltså inte kan köras självständigt, kallas för en relaterad eller sammankopplad fråga, eller på svengelska korrelerad fråga, efter engelskans correlated query.
Eftersom det bara finns en kolumn som heter Medlem, och en som heter Mnr, kan de inte förväxlas med några andra kolumner, och man behöver inte skriva ut vilka tabeller de hör till:
select * from Medlemmar
where exists (select * from Deltar
where Medlem = Mnr);
Om man i stället skriver
select *
from Medlemmar, Deltar
where Deltar.Medlem = Medlemmar.Mnr;
skulle man kunna tro att man får samma svar, men (förutom att det blir fler kolumner i svaret) kommer alla medlemmar som deltar i fler än en sektion nu att komma med flera gånger i svaret.
Det är ett exempel på hur SQL använder påsar i stället för mängder, som vi nämnde på sidan 130.
Med not exists kan man få fram de rader i den yttre frågan som inte ger några rader i den inre, till exempel för att ta reda på vilka medlemmar som inte sportar alls:
select * from Medlemmar
where not exists (select * from Deltar
where Medlem = Mnr);
Vi vill (återigen) varna för att frågan inte kan skrivas om med en olikhet:
select *
from Medlemmar, Deltar
where Medlem <> Mnr;
133
Ibland behöver man jämföra ett värde med flera andra värden, till exempel för att se om det är större (eller mindre) än alla, eller bara något, av de andra värdena. Då kan man använda any, some och all.
Om vi vill veta vilka medlemmar som har ett medlemsnummer som är större än i alla fall någon av de andra medlemmarnas nummer, kan vi använda any (eller some, som betyder samma sak):
select * from Medlemmar
where Mnr > any (select Mnr
from Medlemmar);
Det var bara för Olle, med medlemsnummer 1, som det inte fanns någon annan medlem som hade ett lägre nummer.
Vi använde tabellen Medlemmar i både den inre och den yttre frågan, men det är inget konstigt med det.
Som vanligt när man har en inre fråga kan man se det som att den yttre frågan körs, och sen körs den inre frågan en gång för varje rad som ska kollas i den yttre frågan.
Man gör alltså, kan man säga, flera olika sökningar i samma tabell, men det finns ingen risk att de skulle blandas ihop på något sätt.
Finns det någon som har ett medlemsnummer som är större än alla medlemsnummer?
select * from Medlemmar
where Mnr > all (select Mnr
from Medlemmar);
Här skulle man kanske förväntat sig att Lotta, med medlemsnummer 4, skulle ha kommit med i svaret, för hon har ju ett medlemsnummer som är större än alla andras.
Men tänk på att den inre frågan tar fram alla medlemsnummer, inklusive Lottas eget.
Därför kommer den yttre frågan inte att ge några rader alls i svaret, för inte ens Lotta har ju ett nummer som är högre än hennes eget nummer.
134
Ibland vill man ha raderna i svaret sorterade i en viss ordning. Det görs enkelt med konstruktionen order by, som placeras allra sist i SQL-frågan:
select Namn, Telefon
from Medlemmar
where Mnr > 2
order by Namn;
Man kan ange en kombination av flera olika kolumner att sortera efter, och man kan sortera i stigande eller fallande ordning genom att ange asc (för ascending eller stigande, som är default-värdet) respektive desc (för descending eller fallande). Exempel:
select Medlemmar.Namn, Sektioner.Namn
from Medlemmar, Deltar, Sektioner
where Mnr = Medlem
and Sektion = Skod
order by Medlem.Namn asc, Sektioner.Namn desc;
En intressant sak är att en select-sats med order by returnerar en sekvens, vilket är samma sak som en påse där ordningen mellan raderna har betydelse. Eftersom databashanteraren internt arbetar med påsar och mängder, är order by inte tillåtet inuti frågor, utan bara för det yttersta select-uttrycket i en fråga.
En annan viktig sak som har med order by att göra är urval av rader i resultatet. Man vill ofta ha bara en del av resultatet från en
135
fråga, till exempel för att presentera en skärmsida åt gången för användaren, eller för att få fram en tio-i-topp-lista
13
med de snällaste barnen i jultomtens databas. Det kräver förstås att man också gjort en sortering med order by, för annars kan man ju inte vara säker på vilka rader som blir exempelvis de tio första.
Med moderna databashanterare kan man specificera hur många rader man vill ha i resultatet, för att informera databashanteraren om att man bara är intresserad av de snällaste barnen.
Systemet behöver då inte först hämta, sedan sortera och slutligen slänga bort alla utom de snällaste barnen.
Denna typ av frågor är speciellt användbar för datalager och beslutsstöd, vilket kommer att behandlas i kapitel 18.
Ursprungligen föreslogs syntaxen stop after, men den har inte slagit igenom. SQL-standarden innehåller en ganska krånglig lösning med en funktion som heter row_number(), men många databashanterare har helt andra (och bättre) lösningar.
I MySQL och PostgreSQL använder man nyckelordet limit:
14
select Namn, Lön
from Anställda
where Ålder > 50
order by Lön desc
limit 10;
I MySQL kan man dessutom skriva limit 5,10 för att få rad nummer 6-15, och i PostgreSQL ger limit 10 offset 5 samma resultat.
Som ett annat exempel visar vi hur man kan skriva i Db2:
select Namn, Lön
from Anställda
where Ålder > 50
order by Lön desc
fetch first 10 rows only;
Och i Microsoft SQL Server:
136
select top 10 Namn, Lön
from Anställda
where Ålder > 50
order by Lön desc;
SQL-frågor kan ge svar med väldigt många rader.
När man skriver in SQL-frågor och kör dem direkt i ett textgränssnitt brukar databashanteraren dela upp resultatet i lagom många rader för att visa dem på ett läsbart sätt, men när SQL-frågorna ingår i ett program måste man som programmerare oftast tänka på att bara hämta ett lämpligt antal rader åt gången.
I den föregående SQL-frågan tog vi fram alla de medlemmar som hade ett medlemsnummer som var större än alla medlemsnummer.
Det blev ju ingen, för inte ens den medlem som har det högsta medlemsnumret har ett nummer som är högre än sitt eget.
Men om vi vill ha fram den som har ett högre medlemsnummer än alla andra?
Vi kommer ihåg att den inre frågan (konceptuellt sett) körs en gång för varje rad som ska kollas i den yttre frågan, och att man då (i den inre frågan) kan använda den rad i den yttre frågan som kollas.
Vi skulle alltså kunna lägga till ett where-villkor i den inre frågan som tar med alla medlemmar utom just den som vi just nu tittar på i den yttre frågan.
Ett första försök:
select * from Medlemmar
where Mnr > all (select Mnr
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Medlemmar
where Mnr <> Mnr);
Det där blir förstås alldeles fel, för hur ska databashanteraren kunna veta att vi menar två olika medlemsnummer när vi skriver "Mnr <> Mnr"? När databashanteraren kör den inre frågan kommer den att leta efter tabellnamn och kolumnnamn, som Mnr, i de tabeller som räknas upp på den inre frågans som from-lista, och det är först när den inre frågan nämner en tabell eller kolumn som inte finns med i from-listan som den "hoppar ut" eller "höjer blicken" ett steg, och tittar på den yttre frågan.
137
I det här fallet måste vi ge alias till tabellerna, på samma sätt som vi kommer att se i ett senare stycke:
select * from Medlemmar as gammal
where Mnr > all (select Mnr
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Medlemmar as ung
where ung.Mnr <> gammal.Mnr);
Ordet as kan utelämnas om man vill, och vissa databashanterare tillåter inte att man har med det.
En kort utviktning: Att fråga vem som har ett medlemsnummer som är högre än alla andras är ju samma sak som att fråga vem som har det högsta medlemsnumret. Vi kommer inte att lära oss om så kallade aggregatfunktioner, som max, förrän i ett senare avsnitt, men frågan om vem som har det högsta medlemsnumret uttrycks lättast så här:
select * from Medlemmar
where Mnr = (select max(Mnr)
from Medlemmar);
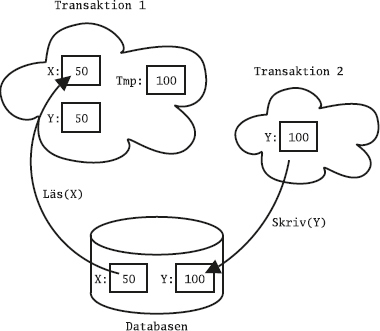
Vi kan inte bara söka i databasens innehåll, utan vi kan också ändra på innehållet. Vi kan lägga till rader med kommandot insert, ta bort rader med delete, och ändra på raders innehåll med update.
select * from Medlemmar;
insert into Medlemmar values (7, 'Isaac', '281000');
select * from Medlemmar;
138
Om det fattas ett värde, till exempel om vi vill lägga in medlemmen Nelson som inte har någon telefon?
insert into Medlemmar values (8, 'Nelson');
Vi får ett felmeddelande:
Mimer SQL error -12233 in function PREPARE
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xThe number of insert values is not the same as the
number of object columns
Om vi inte har värden till alla kolumnerna för en rad, måste vi lista namnen på kolumnerna, så att databashanteraren vet vilka kolumner det är vi faktiskt ska lägga in värden i:
insert into Medlemmar (Mnr, Namn) values (8, 'Nelson');
select * from Medlemmar;
Nelsons telefon fick värdet null.
Nelson har alltså inte något telefonnummer lagrat i tabellen, utan rutan är tom.
Ett null-värde kan betyda olika saker: att Nelson inte har någon telefon, att vi inte vet numret, eller kanske att telefonnummer inte är tillämpliga för medlemmar som är döda engelska amiraler.
Som ett alternativ till att utelämna kolumnen i insert-satsen kan man skriva ut ordet null:
insert into Medlemmar (Mnr, Namn, Telefon)
values (18, 'Nelson', null);
Vi kan söka efter de medlemmar som inte har något telefonnummer:
139
select * from Medlemmar where Telefon is null;
Notera att man måste skriva villkoret som "Telefon is null", och inte "Telefon = null". Null är inte samma sak som talet noll eller en tom sträng, utan det är ett eget värde som just betyder att det inte finns något värde i den rutan i tabellen.
Kan vi lägga in en ny medlem med samma nummer som en existerande medlem?
Det beror på.
Om vi angett att kolumnen Mnr är en nyckel, kommer databashanteraren automatiskt att kontrollera att inga dubbletter läggs in.
Exempel:
insert into Medlemmar
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (4, 'Bengt', '222000');
Mimer SQL error -10101 in function EXECUTE
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xPRIMARY KEY constraint violated, attempt to
insert duplicate key in table Medlemmar
Det fanns redan en medlem med medlemsnummer 4, nämligen Lotta.
Vi kan föregripa avsnittet om hur man skapar tabeller med SQL genom att visa tabelldefinitionen för tabellen Medlemmar:
create table Medlemmar
(Mnr integer not null,
Namn varchar(6),
Telefon varchar(10),
primary key (Mnr));
Här har vi angett vilka kolumner som ska finnas i tabellen, vilka typer av data som går att lägga in i de kolumnerna, och även att Mnr är primärnyckel.
Eftersom det bara är Mnr som måste ha ett unikt värde för varje rad, går det bra att exempelvis lägga in ännu en medlem som heter Nelson:
insert into Medlemmar
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (17, 'Nelson', '281000');
select * from Medlemmar;
140
Man kan även ta raderna i resultatet av en SQL-fråga och lägga in i en tabell.
Ett exempel:
insert into Medlemmar (Mnr, Namn, Telefon)
select Nummer + 10, Namn, null
from Prospects
where Inbetalt >= 100;
Det brukar också finnas kommandon för att läsa in data från en fil till en tabell, men det varierar mellan olika databashanterare hur man skriver.
Vi kan ta bort rader med kommandot delete:
delete from Medlemmar where Namn = 'Isaac';
Databashanteraren svarar, beroende på typ av databashanterare och vilket verktyg vi använder för att ställa SQL-frågor:
1 row deleted
Vi kontrollerar att medlemmen Isaac har försvunnit:
select * from Medlemmar;
delete tar helt enkelt bort alla rader som matchar where-villkoret. Se upp med "delete from Medlemmar", utan where-villkor, som tömmer hela tabellen!
Till sist ska vi också se att vi kan ändra rader med kommandot update:
141
update Medlemmar
set Telefon = '260088'
where Namn = 'Lotta';
Databashanteraren svarar:
1 row updated
Nu ser tabellen ut så här:
Vi provar att använda update för att ändra ett medlemsnummer:
update Medlemmar
set Mnr = 4
where Namn = 'Sam';
Mimer SQL error -10101 in function EXECUTE
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xPRIMARY KEY constraint violated, attempt to
insert duplicate key in table Medlemmar
Det är inget fel att ändra på värdet i en kolumn som är deklarerad som nyckel, men i det här fallet fanns det ju redan en medlem med medlemsnummer 4.
Precis som vid insättning av nya rader kontrollerar databashanteraren att nyckelvillkoret, alltså att varje rad ska ha ett unikt värde i kolumnen Mnr, upprätthålls.
Man kan ändra flera kolumner på en gång:
update Medlemmar
set Mnr = 100, Telefon = '118118'
where Namn = 'Sam';
Det går också bra att ändra på flera rader på en gång med update, och att basera de nya värdena på de gamla. Om vi tillfälligtvis antar att vi har lagrat anställda i tabellen Anställda,
15
och vill höja lönen (kolumnen Lön) för alla som arbetar på dataavdelningen med fem procent, kan vi använda det här kommandot:
142
update Anställda
set Lön = Lön * 1.05
where Avdelning = 'Data';
En vy i SQL är en tabell som inte lagras i databasen, utan vars innehåll räknas ut på nytt varje gång man tittar på den.
(Det kan fungera annorlunda internt i databashanteraren, men det ser alltid ut som om vyns innehåll räknas ut på nytt.)
Man kan också se en vy som en fråga, som man gett ett namn och sparat undan, så att man sen kan köra den på nytt och titta på dess resultat.
Eftersom alla SQL-frågor ger en tabell som resultat, ser vyn ut som om den var en vanlig tabell.
En vydefinition består alltså av en enda SQL-fråga, som definierar vyns innehåll.
Nu ska vi prova på vyer.
Vi börjar med en vanlig SQL-fråga, som visar sektionsnamn tillsammans med namnet på ledaren för den sektionen:
select Sektioner.Namn, Medlemmar.Namn
from Sektioner, Medlemmar
where Ledare = Mnr;
Vi försöker göra en vy av den frågan, med hjälp av kommandot
create view:
create view Ledarskap
as select Sektioner.Namn, Medlemmar.Namn
from Sektioner, Medlemmar
where Ledare = Mnr;
Mimer SQL error -12252 in function EXECUTE
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xCREATE VIEW statement must include a
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xcolumn list because the SELECT clause
contains duplicated column name Namn
143
Det misslyckades.
I svaret på en fråga, som bara ska skrivas ut, kan man tillåta två kolumner med samma namn, men inte i en vy eller tabell.
Precis som det står i felmeddelandet måste vi ge namn till kolumnerna i vyn, till exempel så här:
create view Ledarskap (Sektionsnamn, Ledarnamn)
as select Sektioner.Namn, Medlemmar.Namn
from Sektioner, Medlemmar
where Ledare = Mnr;
Alternativt kan man använda as för att ge kolumnerna nya namn:
create view Ledarskap
as select Sektioner.Namn as Sektionsnamn,
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xMedlemmar.Namn as Ledarnamn
from Sektioner, Medlemmar
where Ledare = Mnr;
Nu fungerar vyn som vilken tabell som helst (i alla fall så länge vi bara ska titta på innehållet, och inte försöker ändra det):
select * from Ledarskap;
select Ledarnamn
from Ledarskap
where Sektionsnamn = 'Bowling';
Ledarnamn
Lotta
Eftersom en vy i SQL är en lagrad SQL-fråga, kan vyer vara lika komplicerade som godtyckliga SQL-frågor.
16
En skillnad mellan vyer och vanliga tabeller är att vyer vanligen inte kan uppdateras.
En del databashanterare tillåter att man gör ändringar i innehållet i en vy, och dessa ändringar slår då igenom till de tabeller som vyn baseras på, men det finns många ändringar som databashanteraren inte kan lyckas med.
Antag till exempel att vi ger följande kommando:
144
update Ledarskap
set Ledarnamn = 'Lotta'
where Sektionsnamn = 'Konstsim';
Den ändringen skulle kunna genomföras genom att vi byter ledare för konstsimsektionen från Stina till Lotta, med en ändring av kolumnen Ledare i tabellen Sektioner.
Men den skulle också kunna göras genom att vi byter namn på medlemmen Stina till Lotta, och alltså ändrar i kolumnen Namn i tabellen Medlemmar.
Databashanteraren kan inte veta vilken av dessa ändringar vi vill göra och ger därför ett felmeddelande.
I regel kan vyer som kombinerar tabeller inte uppdateras.
En allmän regel är att vyer över en enda tabell som inkluderar dess primärnyckel kan uppdateras, som till exempel:
create view Medlemsnamn
as select Mnr, Namn from Medlemmar;
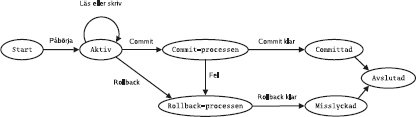
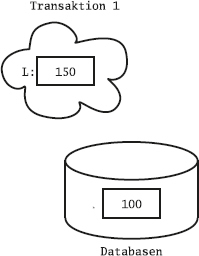
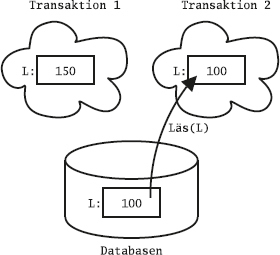
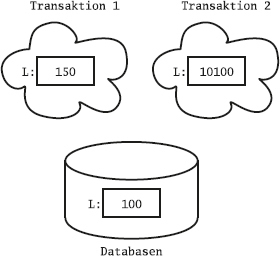
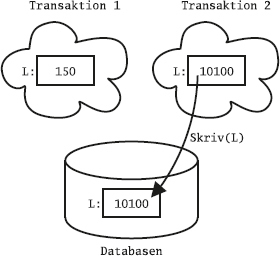
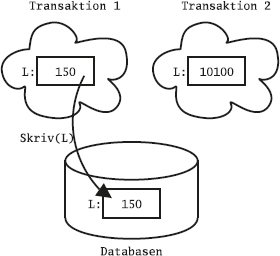
Det flesta relationsdatabashanterarna har något som kallas transaktioner, vilket bland annat innebär att de kan gruppera flera SQL-satser till en enhet, vars ändringar gemensamt antingen kan sparas i databasen eller kastas bort. För att styra det använder man SQL-kommandona commit och rollback.
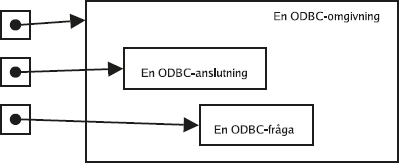
Ofta är default-inställningen att varje SQL-kommando räknas som en egen transaktion, så kallad auto-commit, och då måste man explicit slå på transaktionshanteringen för att kunna gruppera ihop flera SQL-satser till en transaktion. Man brukar använda kommandot start transaction för att påbörja en transaktion som sträcker sig över flera satser. I en del system kallas det i stället begin transaction. Om man använder SQL inifrån ett program, till exempel med ODBC eller JDBC, finns det särskilda anrop för att slå på transaktionshanteringen. Ibland kallas det att "stänga av autocommit".
Vi startar en transaktion, och studerar än en gång innehållet i tabellen Sektioner:
start transaction;
select * from Sektioner;
145
Lägg till en ny sektion i tabellen:
insert into Sektioner values ('D', 'Brännboll', 3);
Kontrollera innehållet:
select * from Sektioner;
Ge kommandot commit:
commit;
I och med att vi gjort commit, är ändringarna "sparade" i databasen.
De kommer inte att försvinna om datorn kraschar eller om strömmen går, och i ett fleranvändarsystem blir de nu synliga för andra användare.
Nu kan vi göra fler ändringar, i en ny transaktion:
start transaction;
delete from Sektioner where Namn = 'Brännboll';
insert into Sektioner
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues ('E', 'BASE-hoppning', 3);
update Sektioner set Namn = 'Maraton'
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xwhere Namn = 'Bowling';
select * from Sektioner;
146
Nu ångrar vi oss. Vi vill ha tillbaka brännbollen, BASE-hoppning
17
är alltför farligt, och medlemmarna i bowlingsektionen är mycket missnöjda med att deras trevliga bowlingkvällar gjorts om till träning för maratonlopp. Därför kastar vi bort ändringarna sen senaste commit genom att ge kommandot rollback. Och plötsligt är allting som förut:
rollback;
select * from Sektioner;
Databasens schema kan ändras.
Både tabeller och vyer kan ändras så att de får fler, eller färre, kolumner än de hade från början.
När man skriver SQL-kommandon "ad hoc", dvs som man skriver in direkt, för hand, och som ska köras en enda gång, kan man strunta i det.
Men SQL-kommandon som ska finnas kvar länge och köras många gånger, till exempel om de ingår i ett program eller ett skript, kan ge problem om databasens schema ändras.
Ta denna fråga:
select * from Medlemmar;
Tabellen Medlemmar kanske har de tre kolumnerna Mnr, Namn och Telefon. Om frågan ingår i ett program, skriver vi kanske programkod för att hantera tre värden från varje rad i resultatet. Men så ändrar någon tabellen (med SQL-kommandot alter table) och lägger till en fjärde kolumn, Adress. Nu ger frågan plötsligt fyra värden per rad, och om programmet inte kan hantera det, kanske det slutar fungera. Skriv hellre ut de kolumner som faktiskt ska hämtas:
select Mnr, Namn, Telefon from Medlemmar;
147
Om tabellens schema ändras kommer programmet fortfarande att fungera.
Det kan inte hantera den nya kolumnen med adresser, men programmet klarar i alla fall att jobba vidare med de tre gamla kolumnerna.
Ett liknande problem kan uppstå med frågor som den här (från sidan 124):
select Medlemmar.Namn
from Sektioner, Medlemmar
where Ledare = Mnr
and Sektioner.Namn = 'Bowling';
Kolumnen Namn fanns, som vi kanske kommer ihåg, i båda tabellerna, och därför måste vi ange vilket namn vi menar, som med Medlemmar.Namn. Kolumnerna Ledare och Mnr fanns bara i en av tabellerna, så där behövdes det inte. Men vad händer om någon ändrar någon av tabellernas schema och exempelvis lägger till en kolumn Ledare även i tabellen Medlemmar? Då finns det plötsligt två kolumner med samma namn att välja mellan, och frågan slutar fungera. Därför kan det vara bra att alltid ange tabellnamnen i SQL-kommandon som ska användas länge:
select Medlemmar.Namn
from Sektioner, Medlemmar
where Sektioner.Ledare = Medlemmar.Mnr
and Sektioner.Namn = 'Bowling';
Förutom ett frågespråk eller datamanipuleringsspråk är SQL även ett datadefinitionsspråk eller DDL,
18
dvs ett språk som man kan beskriva databasens schema med. I en relationsdatabashanterare betyder det att man skapar tabeller, och det gör man med kommandot create table. Det kan se ut så här:
create table Sektioner
(Skod char(1) not null,
Namn varchar(14),
Ledare integer,
primary key (Skod),
unique (Namn),
148
foreign key (Ledare) references Medlemmar (Mnr));
Här skapade vi en tabell som heter Sektioner. Mellan parenteserna räknade vi upp tabellens kolumner, och vilka datatyper de har. Char(1) betyder ett textfält som innehåller ett enda tecken.
Varchar(14) betyder ett textfält som kan innehålla från noll upp till fjorton tecken. Integer betyder heltal. Det finns fler datatyper i SQL, till exempel date som betyder datum. Det kan variera lite mellan olika databashanterare vilka datatyper som finns och vad de heter.
Not null, som står efter kolumnen Skod, anger förstås att den kolumnen inte får innehålla några null-värden.
För att undvika null-värden kan man ange ett defaultvärde för en kolumn, till exempel så här:
Namn varchar(14) default 'Felix',
Om man lägger in en ny rad i tabellen (med insert) och inte sätter den kolumnens värde, sätter databashanteraren automatiskt in defaultvärdet i stället. Eftersom null-värden orsakar en del problem när man ställer frågor
19
är det ofta bra att använda defaultvärden, om de understöds av databashanteraren.
Primary key (Skod) anger vad som är primärnyckel i tabellen, nämligen kolumnen Skod. En primärnyckel kan vara sammansatt av flera kolumner, och då räknar man upp dem med komma emellan. Förutom att primärnyckeln inte får ha samma värde på två olika rader, får den inte innehålla några null-värden. En del databashanterare (men inte alla) kräver därför att man skriver not null på de kolumner som ingår i primärnyckeln.
Om man har en alternativnyckel, dvs en annan kolumn eller kombination av kolumner som också skulle kunna användas som primärnyckel, kan man specificera det med nyckelordet unique, till exempel som unique (Namn).
Foreign key (Ledare) references Medlemmar (Mnr) anger att Medlem är ett referensattribut, eller främmande nyckel som det också kallas, som refererar till kolumnen Mnr i tabellen Medlemmar. Ett referensattribut ska alltid referera till en nyckel.
Nyckel- och referensvillkor som bara berör en enda kolumn (alltså inte nycklar som är sammansatta av flera kolumner), kan skrivas
149
direkt i definitionen av den kolumnen, som kolumnvillkor i stället för som tabellvillkor.
Följande definition av tabellen Medlemmar är ekvivalent med den föregående:
create table Sektioner
(Skod char(1) not null primary key,
Namn varchar(14) unique,
Ledare integer references Medlemmar (Mnr));
Om man har fler villkor som man vill att databashanteraren ska hjälpa till att hålla reda på, kan man skriva dit dem med nyckelordet check.
Här är ett exempel på en tabell med flera olika villkor:
create table Blaj77
(Nummer integer,
Florp integer check (Florp in (1, 17, 4711)),
Fnyyb integer check (Fnyyb > 17 and Fnyyb < 123
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xor Fnyyb = -1),
primary key(Nummer),
check (Florp is null or Fnyyb > 100));
Som illustration av SQL som datadefinitionsspråk visar vi här hur vi skapade tabellerna i idrottsdatabasen.
20
Som vi ser kan man använda kommandot alter table för att ändra en tabells definition, till exempel för att lägga till ett referensattribut. Man kan också lägga in referensattributen direkt i create table-kommandona, men om man har cirkulära referenser måste minst en av dem läggas till i efterhand.
create table Medlemmar
(Mnr integer not null,
Namn varchar(6),
Telefon varchar(10),
primary key (Mnr));
create table Sektioner
(Skod char(1) not null,
150
Namn varchar(14),
Ledare integer,
primary key (Skod));
create table Deltar
(Medlem integer not null,
Sektion char(1) not null,
primary key (Medlem, Sektion));
alter table Sektioner
add foreign key (Ledare) references Medlemmar (Mnr);
alter table Deltar
add foreign key (Medlem) references Medlemmar (Mnr);
alter table Deltar
add foreign key (Sektion) references Sektioner (Skod);
Vi har redan visat hur insert-kommandot kan användas för att lägga till rader i en tabell. För att underlätta för den som vill provköra exemplen visar vi här hur vi ursprungligen la in data i tabellerna i idrottsdatabasen:
151
insert into Medlemmar (Mnr, Namn, Telefon)
values (2, 'Stina', '282677');
insert into Medlemmar (Mnr, Namn, Telefon)
values (3, 'Sam', '260088');
insert into Medlemmar (Mnr, Namn, Telefon)
values (4, 'Lotta', '174590');
insert into Medlemmar (Mnr, Namn, Telefon)
values (1, 'Olle', '260088');
insert into Sektioner (Skod, Namn, Ledare)
values ('A', 'Bowling', 4);
insert into Sektioner (Skod, Namn, Ledare)
values ('C', 'Konstsim', 2);
insert into Sektioner (Skod, Namn, Ledare)
values ('B', 'Kickboxing', 4);
insert into Deltar (Medlem, Sektion)
values (1, 'A');
insert into Deltar (Medlem, Sektion)
values (1, 'B');
insert into Deltar (Medlem, Sektion)
values (1, 'C');
insert into Deltar (Medlem, Sektion)
values (2, 'C');
insert into Deltar (Medlem, Sektion)
values (3, 'A');
En SQL-fråga är inte som ett program i Java eller C, som går att köra direkt, steg för steg.
I stället ska man se SQL-frågan som en regel som specificerar vad man vill ha fram, och databashanteraren måste sen alltid översätta den till de operationer som ska göras på databasen för att beräkna svaret, den så kallade exekveringsplanen.
Det går oftast att göra många olika exekveringsplaner för samma fråga.
Frågan kan ta mycket olika lång tid att köra, beroende på vilken exekveringsplan man väljer.
Det kan röra sig om en skillnad mellan sekunder och år.
Därför optimerar databashanteraren SQL-frågorna.
Frågeoptimering innebär att databashanteraren räknar ut det snabbaste sättet (eller åtminstone ett någorlunda snabbt sätt) att beräkna svaret, med hänsyn tagen till databasens schema, lagringsstruktur och innehåll.
Frågeoptimeraren är helt enkelt den del av databashanteraren som väljer ut den snabbaste exekveringsplanen (eller i alla fall en snabb).
Detta skiljer sig från optimeringssteget i en kompilator för ett vanligt programmeringsspråk som Java eller C, som bara kan göra jämförelsevis enkla omstuvningar av operationerna för att göra programmet snabbare.
154
Därför behöver man inte bry sig om exakt hur man formulerar SQL-frågorna, bara man skriver dem på ett sätt som ger rätt svar.
Databashanteraren kommer ändå att köra dem så snabbt det går.
Emellertid är optimerarna förstås inte ofelbara, och det kan (tvärtemot vad vi påstod i förra stycket) ibland spela roll hur man formulerar frågan.
Vill man att det ska gå fort, bör man skriva flata frågor.
I regel är flata frågor bättre än nästlade frågor både eftersom de är lättare för människor att läsa, och därför att frågeoptimeraren utgår från flata frågor.
En sofistikerad frågeoptimerare kan inte alltid automatiskt transformera en nästlad fråga till en flat.
Men vill man veta säkert måste man mäta, med just det schemat på just den versionen av just den databashanteraren.
Olika databashanterare är olika bra på att optimera olika typer av SQL-frågor, speciellt komplicerade och konstiga frågor.
När en databashanterartillverkare som Microsoft eller Oracle ska mäta prestanda hos sin databashanterare, väljer de förstås gärna en fråga som just deras optimerare råkar lyckas ovanligt bra med, och som konkurrenterna lyckas ovanligt dåligt med.
Därför kan man få se en mätning där databashanteraren Oracle är en miljon gånger snabbare än databashanteraren SQL Server, och en annan mätning där SQL Server är en miljon gånger snabbare än Oracle.
Det säger inte så mycket om hur snabba SQL Server och Oracle är, utan mer om att både Microsoft och Oracle har lagt ned tid på att hitta på konstiga SQL-frågor.
För att på ett (någorlunda) rättvist sätt jämföra olika databashanterare för olika sorters realistiska tillämpningar finns det därför ett antal standardiserade benchmarks.
21
Ett benchmark, eller provbänk på svenska, är en mätning av till exempel snabbhet med syftet att jämföra med andra liknande system.
Dessa databasprovbänkar är utvecklade av TPC, the Transaction Processing Performance Council, som är en oberoende organisation där de ledande databasteknologiföretagen är medlemmar.
Man kan dock inte alltid lita ens på standardiserade provbänkar.
Det är inte ett okänt fenomen att databashanterartillverkare lägger in kod i optimeraren för att specialhantera just de frågor som ingår i proven.
Man kan jämföra med dieselbilsskandalen från 2015.
22
Det ska dock sägas att man i TPC lagt ner en hel del arbete på att få sina
155
provbänkar rättvisa: till exempel automatgenereras databasen, och frågorna är definierade av provbänken.
För den som är intresserad av benchmarks, och hur TPC utvecklades, rekommenderas boken J. Gray (red.): Database and Transaction Processing Performance Handbook, Morgan Kaufmann, 1993, ISBN 1-55860-292-5.
23
159
Kapitel 7 tar upp grunderna om SQL.
I det här kapitlet ska vi titta på lite mer avancerad användning av SQL, främst med aggregatfunktioner, explicit join och yttre join.
Lagrade procedurer och triggers, som också kan räknas till mer avancerad användning av SQL, tas upp i egna kapitel.
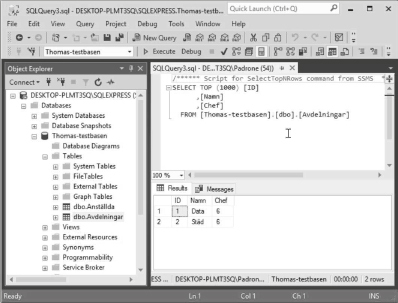
Vi utgår från två enkla tabeller, en som heter Arbetare och en som heter Kontor:
160
Kolumnen Placering refererar förstås till kontorsnumret Knr i den andra tabellen, så att man vet på vilket kontor som varje arbetare arbetar.
För att underlätta för den som vill provköra
1
visar vi här SQL-kommandona för att skapa tabellerna och fylla dem med exempeldata:
2
create table Kontor
(Knr integer,
Knamn varchar(10),
primary key (Knr));
insert into Kontor (Knr, Knamn)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (10, 'Gnesta');
insert into Kontor (Knr, Knamn)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (20, 'Moskva');
insert into Kontor (Knr, Knamn)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (30, 'Pyongyang');
create table Arbetare
(Anr integer,
Anamn varchar(3),
Lön integer,
Placering integer,
foreign key (Placering) references Kontor (Knr),
primary key (Anr));
insert into Arbetare (Anr, Anamn, Lön, Placering)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (1, 'Bob', 1000, 10);
insert into Arbetare (Anr, Anamn, Lön, Placering)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (2, 'Liz', 2000, 10);
insert into Arbetare (Anr, Anamn, Lön, Placering)
values (3, 'Sam', 1000, 30);
161
Vi kan koppla ihop de två tabellerna så man tydligt ser vem som jobbar var:
select *
from Arbetare, Kontor
where Placering = Knr;
Lägg märke till att Moskva-kontoret försvann ur resultatet, eftersom ingen arbetare är placerad på Moskva-kontoret:
En aggregatfunktion arbetar på en hel kolumn, till exempel för att summera alla värden i kolumnen eller för att räkna ut medelvärdet. SQL-standarden innehåller några aggregatfunktioner: avg, som räknar ut medelvärdet, count, som räknar antalet värden i en kolumn,
3
max, som returnerar det största värdet i en kolumn, min, som returnerar det minsta, och sum, som summerar alla värdena. Dessutom finns every, som ger ett sant värde om alla värden den arbetar med är sanna, och any med sin synonym some, som ger ett sant värde om något av de värden den arbetar med är sant.
Vi provar max-funktionen:
select max(Anr) from Arbetare;
max(Anr)
3
Vad kolumnen kommer att heta är olika i olika databashanterare.
Det kan bli max(Anr) som i exemplet, men det kan också bli något annat, eller inget alls.
Det kan vara bra att ge den ett nytt namn:
select max(Anr) as Maxnumret from Arbetare;
162
Maxnumret
3
Ofta vill man inte bara beräkna en aggregatfunktion, utan man vill använda det beräknade värdet för att få fram något annat.
Att få fram det högsta anställningsnumret var lätt, men vem är det som har det numret?
Vi försöker först med den här frågan:
select *
from Arbetare
where Anr = max(Anr);
Det gick inte, och databashanteraren ger ett felmeddelande som till exempel kan se ut så här:
Mimer SQL error -12213 in function PREPARE
Set function not specified in a SELECT clause or
HAVING clause
Felmeddelandet talar om mängdfunktioner (engelska: set function).
Det är den term som används i standarddokumenten, men alla andra säger aggregatfunktioner.
I SQL kan man inte ha aggregatfunktioner direkt i where-villkoret. Vi måste baka in aggregatfunktionen i en underfråga:
select *
from Arbetare
where Anr = (select max(Anr) from Arbetare);
nullvärden ignoreras av aggregatfunktioner, som om de raderna inte alls hade funnits. Medelvärdet avg av 2, 4 och null är alltså 3, inte 2.
Vi använder aggregatfunktionerna sum och avg för att räkna ut summan och genomsnittet av allas löner:
select sum(Lön), avg(Lön)
from Arbetare;
163
Notera att man alltså kan beräkna flera olika aggregatfunktioner i samma fråga.
Man kan kombinera aggregatfunktioner med ett where-villkor, vilket gör att aggregatfunktionen bara beräknas för de rader som uppfyller where-villkoret. Man kan alltså se det som att först körs frågan med where-villkoret, och sen beräknas aggregatfunktionen, på de rader som kom med. Till exempel kan vi ta fram Bob och Sam, och sen beräkna genomsnittet av deras löner:
select avg(Lön)
from Arbetare
where Anamn = 'Bob' or Anamn = 'Sam';
avg(Lön)
1 000
Frågan som körs "först", före aggregatfunktionen, kan vara en mer komplicerad fråga, med flera tabeller.
Till exempel kan vi ta fram genomsnittslönen för alla som arbetar på Gnesta-kontoret:
select avg(Lön)
from Arbetare, Kontor
where Placering = Knr
and Knamn = 'Gnesta';
avg(Lön)
1 500
Som vanligt kan man koppla ihop tabeller antingen genom att räkna upp dem i from-listan och koppla ihop dem i where-villkoret, eller genom att använda en underfråga i where-villkoret. Det här är alltså ett alternativt sätt att skriva samma fråga:
select avg(Lön)
from Arbetare
where Placering = (select Knr from Kontor
where Knamn = 'Gnesta');
164
Vi nämnde ovan att SQL-standarden avänder termen "mängdfunktioner" för det som brukar kallas aggregatfunktioner.
Men när man talar om mängder och vad man kan göra med dem, brukar det handla om mängdoperationer, som arbetar med mängder och ger mängder som svar.
Tabeller i relationsmodellen kan ses som mängder av rader, och därför kan man även i SQL använda de vanliga mängdoperationerna union, snitt och differens.
En mängd är en samling element, utan några dubbletter.
Ett element kan alltså inte vara med i samma mängd två gånger, utan antingen är det med i mängden eller också inte.
En person kan till exempel vara svensk, dvs vara med i mängden svenskar, men hon kan inte vara svensk två gånger.
I följande två mängder, kallade X och Y, innehåller mängden X de tre elementen 1, 2 och 3, medan mängden Y innehåller de två elementen 3 och 4:
Följande figurer visar unionen, snittet respektive differensen av X och Y:
Operationen union finns i många SQL-dialekter, men snitt och differens kan saknas i en del.
165
För att kunna beräkna mängdoperationer på två tabeller i SQL måste de vara unionkompatibla, dvs ha samma antal och datatyp på kolumnerna.
Man kan inte utföra en mängdoperation direkt på två tabeller, utan man gör det på resultatet av två SQL-frågor.
Exempel:
select Anr, Anamn
from Arbetare
where Placering = 10
union
select Anr, Anamn
from Arbetare
where Placering = 30;
Den som studerat matematik och minns sin mängdlära vet att mängdoperationen union och den logiska operationen eller är relaterade: unionen av två mängder är ju de element som finns med i den ena eller den andra mängden, eller båda. Ovanstående SQL-fråga med union är ekvivalent med följande fråga med or:
select Anr, Anamn
from Arbetare
where Placering = 10 or Placering = 30;
För att förenkla frågorna i de efterföljande exemplen kommer vi ihåg att Gnesta-kontoret har nummer 10.
Beräkna alltså genomsnittslönen bara för dem som jobbar på kontoret i Gnesta (nummer 10):
select avg(Lön)
from Arbetare
where Placering = 10;
avg(Lön)
1 500
Vi kan ta båda kontoren, i Gnesta (nummer 10) och Pyongyang (nummer 30) med hjälp av SQL-operationen union:
select avg(Lön)
from Arbetare
where Placering = 10
union
select avg(Lön)
from Arbetare
where Placering = 30;
avg(Lön)
1 000
1 500
Vi nämnde tidigare att mängdoperationen union och den logiska operationen eller är relaterade. Men SQL-frågan ovan, med union, är inte samma sak som den här, med or:
select avg(Lön)
from Arbetare
where Placering = 10 or Placering = 30;
167
avg(Lön)
1 333
Skillnaden är att i det här fallet körs frågan med where-villkoret först, och först därefter beräknas genomsnittet av alla rader som uppfyllde where-villkoret. Det är en annan sak än att först beräkna två olika genomsnitt, och sen ta med båda resultaten i svaret.
Det går inte heller att byta ut or mot and:
select avg(Lön)
from Arbetare
where Placering = 10 and Placering = 30;
avg(Lön)
null
Den frågan söker fram de anställda vars Placering samtidigt är både 10 och 30.
Några sådana finns förstås inte.
Resultatet av aggregatfunktionen blir därför null, eftersom medelvärdet av noll tal är odefinierat.
Om vi vill ha genomsnittslönen för vart och ett av kontoren kan vi alltså använda union för att slå ihop resultaten av flera separata frågor, som vi gjorde ovan med kontor nummer 10 och 30. Det blir mycket enklare om vi i stället använder SQL-konstruktionen group by:
select avg(Lön)
from Arbetare
group by Placering;
avg(Lön)
1 500
1 000
Men vilka kontor gäller dessa genomsnitt, och i vilken ordning kommer de?
Om vi tar med den kolumn som vi använde för grupperingen även i svaret, så blir det mycket tydligare:
select Placering, avg(Lön)
from Arbetare
group by Placering;
168
Man kan fortfarande ha ett where-villkor, som i så fall görs först, före aggregatfunktionen:
select Placering, avg(Lön)
from Arbetare
where Anamn = 'Bob' or Anamn = 'Sam'
group by Placering;
Se det som att först körs frågan med where-villkoret:
select *
from Arbetare
where Anamn = 'Bob' or Anamn = 'Sam';
och sen beräknas aggregatfunktionen på resultatet från den frågan.
Genom att använda nyckelordet having kan man ta med bara vissa av grupperna i svaret:
select Placering, avg(Lön)
from Arbetare
group by Placering;
select Placering, avg(Lön)
from Arbetare
group by Placering
having avg(Lön) > 1000;
(Ja, 1 000 är inte mer än 1 000.) Man kan ha where, group by och having i samma fråga:
select Placering, avg(Lön)
from Arbetare
169
where Anamn = 'Bob' or Anamn = 'Sam'
group by Placering
having avg(Lön) > 1000;
Placering avg(Lön)
Resultatet blev en tom tabell, för ingen av grupperna hade mer än 1 000 i genomsnittslön:
select Placering, avg(Lön)
from Arbetare
where Anamn = 'Bob' or Anamn = 'Sam'
group by Placering;
Kom ihåg: Först frågan med where-villkoret som "väljer ut rader", sen aggregatfunktionerna (eventuellt uppdelade i grupper med group by), sist
having-villkoret som "väljer ut grupper"
Vi kan ha fler än en tabell i den där frågan som körs först:
select *
from Arbetare, Kontor
where Placering = Knr;
(Samma som tidigare.)
select Knamn, avg(Lön)
from Arbetare, Kontor
where Placering = Knr
group by Knamn;
Igen: Se det som att man kör den vanliga "select * from ... where ..." först, och sen kör man aggregatfunktionerna.
Vi har tidigare sett hur man kan koppla ihop de två tabellerna, så man ser vem som jobbar var:
select *
from Arbetare, Kontor
where Placering = Knr;
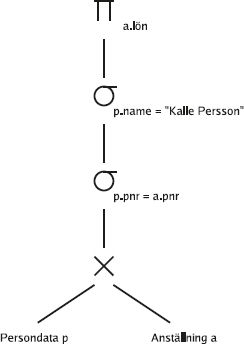
Om vi för ett ögonblick ska prata relationsalgebra i stället för SQL, så har vi kopplat ihop de två tabellerna med en join-operation, under
171
villkoret Placering = Knr.
Om man skriver joinen av de två tabellerna med ett relationsalgebrauttryck, ser det ut så här:
Arbetare P lacering=Knr Kontor
En join av den här typen brukar kallas "vanlig" join eller inre join.
Det finns nämligen också något som kallas yttre join, som vi kommer att ta upp senare i det här kapitlet.
Så här skulle man kunna rita upp det:
Lägg märke till att Moskva-kontoret försvann ur resultatet, för det finns ingen arbetare som är placerad på Moskva-kontoret:
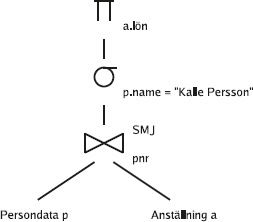
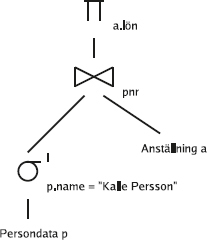
SQL har utökats med relationsalgebraoperatorn join som ett alternativt sätt att formulera frågor som kombinerar tabeller.
Det här kan man skriva med en explicit join i from-listan:
select *
from (Arbetare join Kontor on Placering = Knr);
Man kan se det som att först beräknas joinen och blir en ny tabell, och sen ingår den i from-listan precis som en vanlig tabell.
Vi kan också lägga på ett where-villkor som vanligt, till exempel för att bara få med de arbetare som jobbar i Gnesta:
select *
from Arbetare, Kontor
where Placering = Knr and Knamn = 'Gnesta';
Alternativt, med en explicit join:
172
select *
from (Arbetare join Kontor on Placering = Knr)
where Knamn = 'Gnesta';
Man kan se det som att först skapas "tabellerna i from-listan", genom att explicita joinar beräknas, och sen körs frågan.
4
Vi ska senare se hur man kan koppla ihop fler än två tabeller med explicita joinar, eller en blandning av explicita och implicita joinar.
Notera att när vi joinar två tabeller, vare sig implicit,
select *
from Arbetare, Kontor
where Placering = Knr;
eller explicit,
select *
from (Arbetare join Kontor on Placering = Knr);
så försvinner de rader som inte går att koppla ihop med en annan rad: kontoret i Moskva försvinner.
I en vanlig join försvinner alla rader som inte går att koppla ihop med en eller flera rader i den andra tabellen.
I en yttre join behåller man dem.
Eftersom det inte finns någon rad att koppla ihop dem med, fyller man på med null-värden.
select *
from (Arbetare right outer join Kontor
on Placering = Knr);
173
En höger-ytter-join (engelska: right outer join) behåller alla rader i den högra tabellen.
Dessutom finns vänster-ytter-join (engelska: left outer join), som behåller alla rader i den vänstra tabellen, och full yttre join (engelska: full outer join), som behåller alla rader i båda tabellerna.
De har tre olika relationsalgebrasymboler, som skapas genom att ta den vanliga fjärilsliknande join-symbolen (⋈) och lägga på ett par streck på vänster sida för vänster-ytter-join (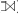 ), på höger sida för höger-ytter-join (
), på höger sida för höger-ytter-join (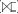 ) eller på båda sidorna för full yttre join (
) eller på båda sidorna för full yttre join (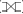 ).
).
Om man skriver joinen som vi gjorde ovan av de två tabellerna med ett relationsalgebrauttryck, ser det ut så här:
Arbetare
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#x 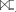 Placering=Knr
Kontor
Placering=Knr
Kontor
Vi kan utgå från frågan ovan, med dess yttre join, och beräkna aggregatfunktioner som summor och genomsnitt:
select avg(Lön)
from (Arbetare right outer join Kontor
on Placering = Knr);
Men borde det inte bli 1 000?
Summan av lönerna är 1 000 + 2 000 + 1 000, dvs 4 000, och det finns fyra rader?
Nej, null är inte 0, utan betyder att det inte är något värde alls. Null-värden ignoreras vid beräkningen av aggregatfunktioner, som om den raden inte alls hade varit med.
Som vi lärt oss tidigare kan vi använda group by för att beräkna flera olika genomsnitt, och det kan vi förstås göra även tillsammans med den yttre joinen:
select Knamn, avg(Lön)
from (Arbetare right outer join Kontor
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xon Placering = Knr)
group by Knamn;
Man kan ha flera aggregatfunktioner i samma resultat:
select Knamn, avg(Lön), sum(Lön)
174
from (Arbetare right outer join Kontor
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xon Placering = Knr)
group by Knamn;
Det kan vara opraktiskt att få null i summan, till exempel om SQL-frågan körs inifrån ett Java- eller C-program och programmet ska jobba vidare med resultatet. Vi vill inte att programmet ska krascha för att det försöker följa en null-pekare! Vi kan använda funktionen coalesce
5
för att byta ut null-värden mot 0:
select Knamn, avg(Lön), coalesce(sum(Lön), 0)
from (Arbetare right outer join Kontor
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xon Placering = Knr)
group by Knamn;
Vi har också projekt som de anställda kan jobba på:
Varje arbetare kan jobba på flera olika projekt, och flera arbetare kan jobba på varje projekt.
Det finns alltså ett många-till-mångasamband mellan arbetarna och projekten, och det uttrycks med en tabell:
176
SQL-kod för att skapa de här två nya tabellerna, och fylla dem med exempeldata:
6
create table Projekt
(Pnr integer,
Pnamn varchar(10),
primary key (Pnr));
insert into Projekt (Pnr, Pnamn)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (100, 'Apollo');
insert into Projekt (Pnr, Pnamn)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (200, 'Manhattan');
insert into Projekt (Pnr, Pnamn)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (300, 'Zork');
create table Jobbar
(Arbetare integer,
Projekt integer,
primary key (Arbetare, Projekt),
foreign key (Arbetare) references Arbetare(Anr),
foreign key (Projekt) references Projekt(Pnr));
insert into Jobbar (Arbetare, Projekt)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (1, 100);
insert into Jobbar (Arbetare, Projekt)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xvalues (1, 200);
insert into Jobbar (Arbetare, Projekt)
values (2, 200);
Vem jobbar var?
select *
from Arbetare, Jobbar, Projekt
where Anr = Arbetare and Projekt = Pnr;
177
Bob jobbar alltså på Apollo-projektet och på Manhattan-projektet.
Liz jobbar också på Manhattan-projektet.
Sam jobbar ingenstans.
Ingen jobbar på Zork-projektet.
Frågan innehåller implicit två (vanliga, inre) joinar, som kopplar ihop de tre tabellerna:
Här är tre olika frågor som kan göra samma sak, men med explicita joinar:
select *
from (Arbetare join Jobbar on Anr = Arbetare)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xjoin Projekt on Projekt = Pnr;
select *
from Arbetare join
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#x(Jobbar join Projekt on Projekt = Pnr)
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xon Anr = Arbetare;
select *
from Arbetare join Jobbar on Anr = Arbetare
join Projekt on Projekt = Pnr;
Man kan kombinera, och ha en explicit och en implicit join:
select *
from (Arbetare join Jobbar on Anr = Arbetare), Projekt
where Projekt = Pnr;
select *
from Arbetare, (Jobbar join Projekt on Projekt = Pnr)
where Anr = Arbetare;
Men man får se upp när man har en yttre join.
Låt oss säga att jag vill ha med alla arbetarna i resultatet, även dem som inte arbetar på något projekt (dvs Sam), med null-värden i de övriga kolumnerna:
178
Vi provar:
select *
from (Arbetare left outer join Jobbar
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xon Anr = Arbetare),
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xProjekt
where Projekt = Pnr;
Ingen Sam!
Som vanligt kan man byta ut en implicit join mot en explicit, så frågan är ekvivalent med
select *
from (Arbetare left outer join Jobbar
on Anr = Arbetare)
join Projekt on Projekt = Pnr;
Dvs, först räknar vi ut den yttre joinen:
select * from (Arbetare left outer join Jobbar
on Anr = Arbetare);
Sen joinar vi den (med en vanlig inre join) med tabellen Projekt:
Joinvillkoret är Projekt = Pnr, men kolumnen Projekt är null i resultatet av den yttre joinen. Det finns inga rader i tabellen Projekt som matchar.
179
(Det skulle inte göra det, även om det fanns en rad där Pnr är null, för null = null är falskt i SQL. Värre ändå: null <> null är också falskt i SQL. Kom ihåg: null är inte ett värde. Alla jämförelser med null, utom den särskilda is null, ger svaret falskt.)
Prova med en yttre join med tabellen Projekt:
select *
from (Arbetare left outer join Jobbar
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xon Anr = Arbetare)
left outer join Projekt on Projekt = Pnr;
Rätt svar!
Man skulle också kunna göra så här, med först en vanlig join mellan Jobbar och Projekt, och sen vänster-ytter-joinar vi Arbetare med resultatet av den inre joinen:
select *
from Arbetare left outer join
(Jobbar join Projekt on Projekt = Pnr)
on Arbetare = Anr;
Krångligt?
Ja, det tycker en hel del databashanterare också, och gör fel.
7
Vilka arbetare har lika lön som någon annan? Vi använder två alias, a1 och a2, som båda refererar till tabellen Arbetare:
8
select a1.Anamn, a1.Lön
from Arbetare as a1, Arbetare as a2
where a1.Lön = a2.Lön;
Alla, varav en del två gånger?
Jo, a1 och a2 kan "peka" på samma rad.
Om vi har med även data från a2-raden syns det tydligare:
183
select a1.Anamn, a1.Lön, a2.Anamn, a2.Lön
from Arbetare as a1, Arbetare as a2
where a1.Lön = a2.Lön;
Vi måste ändra frågan så att vi inte längre får med kombinationerna av en person med sig själv:
select a1.Anamn, a1.Lön
from Arbetare as a1, Arbetare as a2
where a1.Lön = a2.Lön
and a1.Anr <> a2.Anr;
Som vi sett tidigare är null i SQL lite besvärligt att hantera. Även om vi ofta talar om "nullvärden" är det egentligen inte ett värde, utan betyder att "rutan är tom". Det kan i sin tur betyda olika saker: att saken i fråga inte finns ("den medlemmen har ingen telefon"), att den finns, men värdet är okänt ("hon har telefon, men vi vet inte numret"), eller att den uppgiften inte är tillämplig. Dessutom kan nullvärden dyka upp i resultat av SQL-frågor, till exempel yttre join. Dessa olika betydelser kan orsaka förvirring.
Dessutom har null särskilda egenskaper i SQL. Alla jämförelser med null blir falska. Exempelvis skulle man kunna tro att följande fråga skulle ge oss alla raderna i tabellen Medlemmar:
select * from Medlemmar
where Telefon = null or Telefon <> null;
I stället ger frågan inga rader alls i resultatet, eftersom alla jämförelser med null ger resultatet falskt. Null är varken lika med eller
184
skilt ifrån null! För att jämföra med null måste man använda is null, och följande fråga ger alla raderna:
select * from Medlemmar
where Telefon is null or Telefon is not null;
(Konstruktionen Telefon is not null är bara ett alternativt sätt att skriva not Telefon is null.)
Dessutom fungerar null på ett sätt som kan vara lite oväntat i samband med aggregatfunktioner, som vi sett ovan med sum.
Här är ett lite längre exempel på oväntade resultat som man kan få när det är nullvärden inblandade.
Antag att vi har en tabell med Kloka personer, och en med Vackra:
Som vi ser är Anna både klok och vacker, medan Bertil och Cecilia visserligen är kloka, men inte vackra.
Vi kan söka fram de kloka och vackra med SQL:
select * from Kloka
where Namn in (select Namn from Vackra);
Vi kan också söka fram dem som är kloka, men inte vackra:
select * from Kloka
where Namn not in (select Namn from Vackra);
Vad händer nu om vi lägger till ett nullvärde i tabellen Vackra?
insert into Vackra (ID, Namn) values (3, null);
Nu ser tabellerna ut så här:
185
Vi söker än en gång fram de kloka och vackra, med precis samma SQL-fråga som förut, och vi får samma resultat som då:
select * from Kloka
where Namn in (select Namn from Vackra);
Vi försöker också söka fram de kloka, men inte vackra, fortfarande med precis samma SQL-fråga som förut:
select * from Kloka
where Namn not in (select Namn from Vackra);
Nu blev resultatet tomt!
Eftersom det finns ett nullvärde i kolumnen Namn i tabellen Vackra, anser SQL alltså att det inte finns några personer som är kloka men inte vackra!
Det beror förstås på att jämförelser med null alltid ger resultatet falskt i SQL, och skrivsättet not in döljer en jämförelse mellan de båda Namn-kolumnerna i tabellerna.
Vill man ha en förklaring som känns logisk kan man tänka så här: Null betyder att det saknas ett namn i tabellen.
Det finns alltså en vacker person som antingen inte har något namn, eller vars namn vi inte vet, eller så vet vi inte vilken person det är.
Om det är en person som vi inte vet vilken det är, skulle det mycket väl kunna vara någon av Bertil eller Cecilia.
Därför kan vi inte veta att vare sig Bertil eller Cecilia inte är vackra, och vi kan inte ta med dem i resultatet med personer som är kloka men inte vackra.
Det kan vara ett gott råd att försöka undvika nullvärden i sina databaser.
Man kan ange integritetsvillkoret not null på kolumnerna när man skapar tabeller, och man kan konstruera sin databas på ett sätt som gör att nullvärden undviks (se kapitel 6).
En del går så långt att de i stället för null inför särskilda värden i databasen för att markera att värdet saknas, till exempel ett telefonnummer
186
000000 eller TELEFON-SAKNAS.
Det ger dock andra problem, så om man verkligen behöver nullvärden ska man inte vara rädd för att använda dem.
Det finns saker som är svåra eller t.o.m. omöjliga att göra som en enkel select-sats. Ett exempel är att stega sig igenom en hierarki. När teoretikerna pratar brukar detta kallas transitivt hölje (på engelska transitive closure, eller oftare recursive closure).
Vi har en tabell Anställda, och i den finns en kolumn Chef som anger vem som är den anställdes närmaste chef:
De anställda utgör en hierarki.
Vi kan se att anställd nummer 2, som heter Stina, verkar vara högsta chef i företaget.
Hon har två underställda, Sam och Lotta, som i sin tur har underställda, och så vidare.
Givet en viss person, till exempel Petter (nummer 10) är det lätt att ta fram den personens chef med en SQL-sats:
select boss.Nummer, boss.Namn
from Anställda as proletär, Anställda as boss
where proletär.Nummer = 10
and proletär.Chef = boss.Nummer;
Man kan också gå två nivåer upp i hierarkin, och hitta den anställdes chefs chef:
select överboss.Nummer, överboss.Namn
187
from Anställda as proletär,
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xAnställda as mellanboss,
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xAnställda as överboss
where proletär.Nummer = 10
and proletär.Chef = mellanboss.Nummer
and mellanboss.Chef = överboss.Nummer;
Om vi vill ha fram Petters chefer på båda nivåerna direkt ovanför honom, kan vi använda operationen union för att slå samman de båda svaren:
select boss.Nummer, boss.Namn
from Anställda as proletär, Anställda as boss
where proletär.Nummer = 10
and proletär.Chef = boss.Nummer
union
select överboss.Nummer, överboss.Namn
from Anställda as proletär,
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xAnställda as mellanboss,
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xAnställda as överboss
where proletär.Nummer = 10
and proletär.Chef = mellanboss.Nummer
and mellanboss.Chef = överboss.Nummer;
Så länge vi vet hur många nivåer upp vi ska gå, kan vi skriva en SQL-sats. Men om uppgiften är att hitta den anställdes alla chefer, oberoende av om de befinner sig en, två eller kanske hundra nivåer upp i hierarkin, blir det svårare. Det är den typen av operation, att ta sig igenom exempelvis en hierarki i godtyckligt många nivåer, som kallas transitivt hölje, och den går inte alltid att göra i en vanlig select-sats. Inte heller den enklare operationen, att bara få fram den högsta chefen, går alltid att göra med en select-sats. Vi skulle nämligen behöva någon form av repetition eller rekursion, som kan stega sig uppåt i hierarkin godtyckligt många nivåer, ända tills vi når den högsta chefen, och det finns inte i SQL.
Från SQL:1999 finns det i SQL-standarden en mekanism med rekursiva frågor i form av en with recursive klausul i select-satsen
188
som kan användas för att beräkna transitivt hölje. Den är implementerad i de flesta moderna relationsdatabaser, inklusive Oracle, SQL Server, Db2, MariaDB och PostgreSQL, men inte i till exempel MySQL och Mimer. Så här uttrycker man en rekursiv fråga som finner högsta chefen för alla anställda:
with recursive BigBoss(Nummer, Superboss) as(
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xselect a.Nummer, a.Nummer
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Anställda a
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xwhere a.Chef is null
union
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xselect a.Nummer, b.Superboss
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Anställda a, BigBoss b
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xwhere a.chef = b.Nummer
)
select a.Nummer, a.Namn, b.Superboss
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Anställda a, BigBoss b
where a.Nummer = b.Nummer;
Alla har alltså Stina som superboss, inklusive Stina själv. Vad vi gör här är att definiera en delfråga som heter Superboss och är rekursiv eftersom Superboss refererar till sig själv i sin selectsats.
Det är lätt att modifiera den rekursiva frågan för att hitta alla som har Stina som superboss:
with recursive BigBoss(Nummer, Superboss) as(
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xselect a.Nummer, a.Nummer
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Anställda a
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xwhere a.Chef is null
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xunion
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xselect a.Nummer, b.Superboss
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Anställda a, BigBoss b
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xwhere a.chef = b.Nummer
)
189
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xselect a.Nummer, a.Namn
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xfrom Anställda a, BigBoss b
where a.Nummer = b.Nummer and b.Superboss=2;
En finess med att uttrycka transitiva höljen m.h.a. rekursiva frågor är att cirkulära beroenden upptäcks automatiskt i många databashanterare.
Om vi till exempel gör Petter till Marias chef
9
i PostgreSQL blir det ett sådan cirkulärt beroende eftersom Maria också är Petters chef.
Svaret på frågan blir då:
Maria, Ulrik och Petter har inte lägre någon superboss eftersom Maria och Petter är varandras chefer.
En begränsning med rekursiva frågor är att man bara får referera sig själv en gång i with recursive. Det kallas för linjär rekursion. Det har visat sig att linjär rekursion är tillräckligt i många fall. Om man inte kan uttrycka sin fråga som linjär rekursion, eller om databashanteraren inte har with recursive, kan man implementera transitivt hölje som en lagrad funktion, vilket beskrivs i avsnitt 15.5.
Sammanfattningsvis är ett rekursivt hölje (engelska: transitive closure, men ofta recursive closure) en sambandstyp i en databas som är rekursiv, till exempel att anställda är chefer för varandra, som gör kan man skapa djupa hierarkier eller långa kedjor.
En anställd kan vara chef för en annan anställd, som i sin tur kan vara chef för ytterligare en anställd, och så vidare.
Operationen att stega sig igenom en sådan hierarki eller kedja, och (i det här exemplet) ta
190
fram alla chefer som en viss anställd har över sig, och inte bara den närmaste chefen, kallas transitivt hölje.
SQL:1999 var en mycket större standard än de tidigare (ca 2 200 sidor, jämfört med 600 sidor för SQL-92), och den innehöll många nyheter.
De senare standarderna, SQL:2003 och framåt till (när detta skrivs) SQL:2016, bygger vidare på SQL:1999, och innebär inte en lika stor förändring som från SQL-92 till SQL:1999.
Bland nyheterna i SQL:1999 finns stöd för att definiera mer avancerade datatyper, och för att bättre kunna använda klasser och klasshierarkier i relationsdatabaser.
(Just den finessen är det dock inte så många som använder.)
Man bör komma ihåg att det snarare är så att standarden följer databashanterarna, än att databashanterarna följer standarden.
Att en mekanism kommit med i en ny version av standarden betyder därför inte att den inte funnits i flera olika databashanterare tidigare, men kanske med lite varierande syntax och beteende.
Att en mekanism kommer med i en ny version av standarden betyder inte heller att den kommer att finnas tillgänglig i alla databashanterare, eller att den fungerar likadant i alla databashanterare som har den.
Det sägs att det ännu inte finns en enda databashanterare som klarar hela SQL-92, så man ska nog inte förvänta sig att SQL:1999, eller SQL:2016, ska finnas fullständigt implementerad särskilt snart.
191
Nytt i SQL:1999: Datadefinition
Det finns flera nyheter som berör datatyper i SQL:1999.
-
• En praktisk detalj är det nya kommandot
create table like, som gör att man kan skapa en ny tabell med samma schema som en existerande tabell.
-
• Flera nya inbyggda datatyper:
boolean, BLOB (dvs binary large object) som kan användas för att lagra till exempel bilder och filmsekvenser, CLOB (dvs character binary large object) som är en BLOB som innehåller text, arrayer, och radtypen row som är en sorts poster som kan innehålla flera olika fält.
-
• En möjlighet att definiera egna, namngivna datatyper, så kallade user-defined data types eller UDT:er.
Det kan vara både enkla datatyper, till exempel att datatypen temperatur utgörs av heltal, och datatyper som är sammansatta av flera fält, dvs (återigen) en sorts poster.
Här är ett körexempel från databashanteraren Mimer, som visar hur man kan använda kommandot create domain för att skapa och sedan använda datatypen temperatur:
create domain temperature as int
default 0
check (value >= -273);
create table Temperatures
(ID int primary key,
t temperature);
insert into Temperatures (ID, t) values (1, 17);
insert into Temperatures (ID, t) values (2, -317);
När vi försöker lägga in temperaturen på -317 grader får vi ett felmeddelande:
Mimer SQL error -10102 in function EXECUTE
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xDomain constraint
x#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xx#---6bOYygyTzz-CODE-SPACE-vrjYGfS6Jo---#xdbtek0.SQL_DOMAIN_CHECK_0000064492 violated
for table dbtek0.Temperatures, column t
• Hierarkiskt ordnade tabeller, med undertabeller och supertabeller ("subtables" och "supertables").
Varje rad i en subtabell räknas också som om den var med i supertabellen.
Det här kan
192
användas för att representera klasshierarkier i en relationsdatabas.
Nytt i SQL:1999: Predikat, operatorer och kvantifierare
Man har lagt till flera praktiska finesser.
Här är ett par exempel:
-
• Gamla like, som gör strängmatchning, har kompletterats med mer avancerade strängmatchning med reguljära uttryck med hjälp av operatorn
similar to.
-
• Gamla
group by, som beräknar aggregatfunktioner för grupper (till exempel medellönen för de anställda på varje kontor) har utökats med flera nya och mer avancerade grupperingsfunktioner, som är särskilt användbara i datalager (se kapitel 18): group by grouping sets, som gör att man kan gruppera på flera olika sätt i samma fråga, group by rollup, som gör att man kan gruppera i flera nivåer, och group by cube, som grupperar enligt alla kombinationer av de attribut man anger.
-
• Rekursiva vyer, med det nya kommandot
create recursive view, gör att man kan hantera transitivt hölje i SQL.
Nytt i SQL:1999: Triggers
Många databashanterare har länge haft aktiva regler, eller triggers som de brukar kallas (se kapitel 16, Aktiva databaser och triggers), men med helt olika sätt att skriva dem.
I SQL:1999 kom ett standardiserat sätt för hur reglerna ska skrivas och hur de ska fungera.
Nytt i SQL:1999: SQL/PSM, lagrade procedurer
Många databashanterare har länge haft mekanismer för att skriva funktioner och procedurer i ett språk som består av SQL utökat med kontrollstrukturer som loopar och val (se kapitel 15, Lagrade procedurer), men med olika skrivsätt och olika funktion.
I SQL:1999 kom ett standardiserat sätt.
I standarden kallas de persistent stored modules (PSM), alltså ungefär "moduler som lagras permanent i databasen".
193
Nytt i SQL:1999: SQL/CLI, ett API för SQL-anrop från program
SQL:1999 definierar ett nytt gränssnitt för hur datorprogram i C eller C++ kan köra SQL-frågor mot en databas.
Det fanns sedan tidigare en standard för ESQL (Embedded SQL), men SQL/CLI påminner mer om ODBC.
(I själva verket är det nästan precis likadant som ODBC.)
Standarden kallar det för call-level interface (CLI).
Nytt i SQL:1999: Transaktioner
Transaktioner har funnits länge i databaser, men i SQL:1999 standardiserade man flera nya kommandon, till exempel savepoint och rollback to savepoint.
Nytt i SQL:1999: Säkerhet
De flesta databashanterare har länge haft inbyggda funktioner för att styra användarnas rättigheter till innehållet i databasen, främst med kommandona grant och revoke. SQL:1999 definierar dessutom roller. Med kommandot create role kan man skapa en roll, till exempel sekreterare, som ger ett paket av rättigheter som man kan dela ut till de användare som är sekreterare.









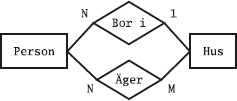


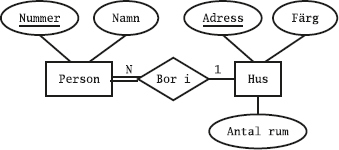
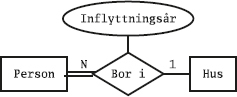


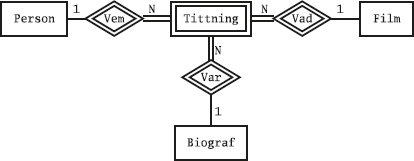
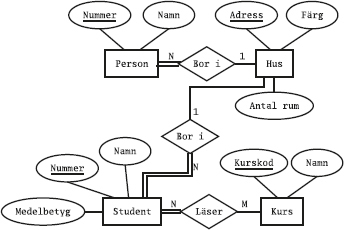

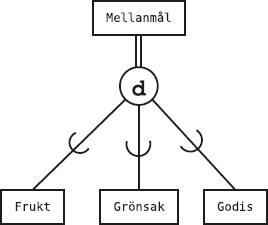
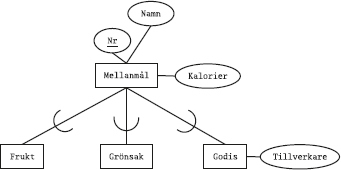
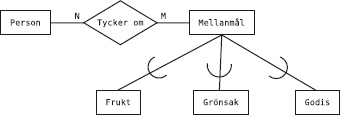

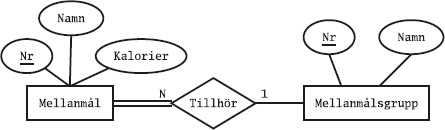

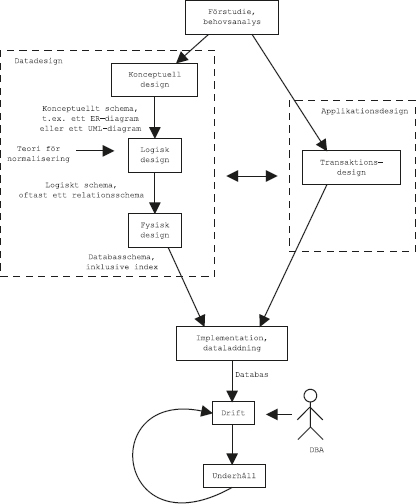
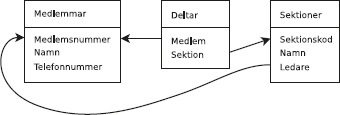
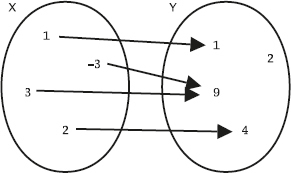
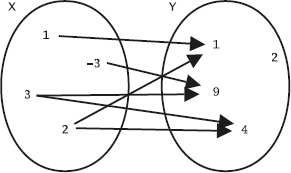
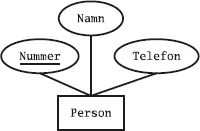
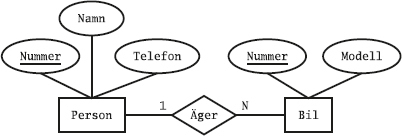
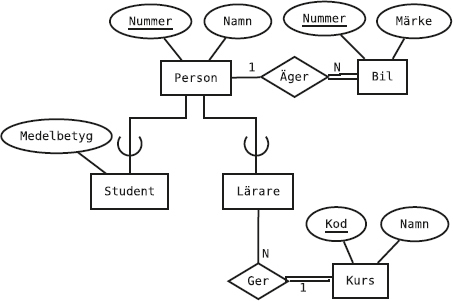
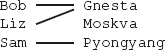
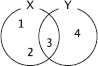
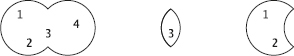
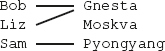


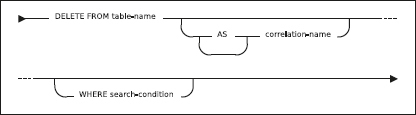
 ), på höger sida för höger-ytter-join (
), på höger sida för höger-ytter-join ( ), och på båda sidorna för full yttre join (
), och på båda sidorna för full yttre join ( ).
).